基于TensorFlow用卷积神经网络做文本分类
原文:Implementing a CNN for Text Classification in TensorFlow
作者:Denny Britz
翻译:Kaiser
本文所部署的模型与Kim Yoon的Convolutional Neural Networks for Sentence Classification相似。论文中的模型在多种文本分类任务(比如情感分析)上都表现良好,现已加入标准基线(baseline)豪华套餐。
我假设你已经非常熟悉卷积神经网络用于自然语言处理的那一套理论了,如果还没的话,建议先阅读前篇:一文读懂CNN如何用于NLP。
数据与预处理
这次要用到的数据集是Movie Review data from Rotten Tomatoes——也是原论文中用到的。数据集包含10662个影评语句样本,正负面各半。数据集词汇量大约2万,注意因为数据量并不大,所以很强的模型反而容易过拟合。数据集本身没有划分出训练/测试,所以我们简单地用10%作为测试集,原论文则是用了10折交叉验证。
数据预处理过程如下:
- 从原始数据文件载入正负样本
- 使用与原论文相同的代码清洗数据
- 在每句话之后添加特别的 token ,把每局话填充到最大句子长度,这里是59。
- 构建词汇索引,将每个词映射到0-18765的整数,每句话就变成了一个整数向量。
模型
本文将要搭建的网络大致如下:
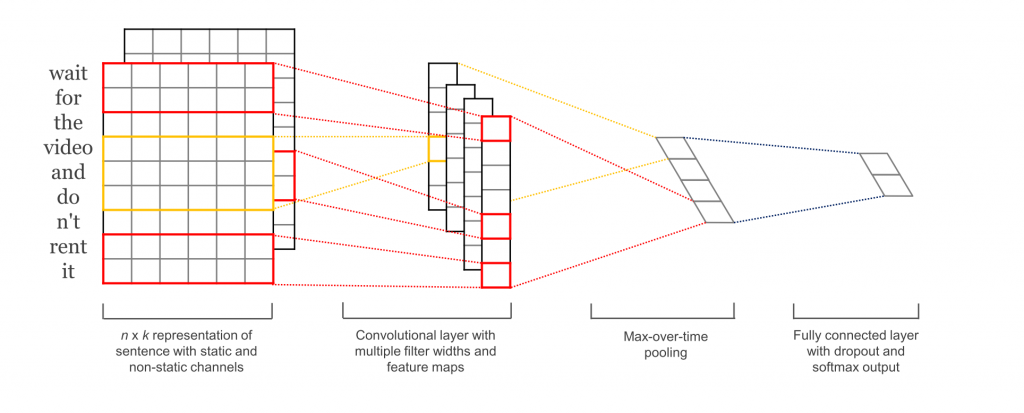
第一层将词嵌入低维向量。下一层用不同大小的卷积核对词嵌入做卷积,每次3-5个词,然后再最大池化获得长特征向量(注:这里的“特征向量”是feature vector,不是eigenvector),经过Dropout正则化之后由softmax分类。
因为是教程文章所以我决定对原论文的模型做些简化:
当然要加上这些扩展也不难,只需要几行代码,可以看本文最后的练习。下面开始说正事:
代码实现
为了便于调教超参数,我们把代码放进名为TextCNN的类里,用init函数生成模型图。
程序说明
定义TextCNN类
示例代码
import tensorflow as tf import numpy as np class TextCNN(object): """ A CNN for text classification. Uses an embedding layer, followed by a convolutional, max-pooling and softmax layer. """ def __init__(self, sequence_length, num_classes, vocab_size, embedding_size, filter_sizes, num_filters): # Implementation...
为了创建对象我们需要传入以下参数:
sequence_length:句子长度,在预处理环节我们已经填充句子,以保持相同长度(59);num_classes:输出层的类别数,这里是2(好评/差评);vocab_size:词空间大小,用于定义嵌入层维度:[vocabulary_size, embedding_size];embedding_size:嵌入维度;filter_size:卷积核覆盖的词汇数,每种尺寸的数量由num_filters定义,比如[3,4,5]表示我们有3 * num_filters个卷积核,分别每次滑过3、4、5个词。num_filters:如上。
占位符
程序说明
占位符
示例代码
class TextCNN(object): def __init__(self, sequence_length, num_classes, vocab_size, embedding_size, filter_sizes, num_filters): # Placeholders for input, output and dropout self.input_x = tf.placeholder(tf.int32, [None, sequence_length], name="input_x") self.input_y = tf.placeholder(tf.float32, [None, num_classes], name="input_y") self.dropout_keep_prob = tf.placeholder(tf.float32, name="dropout_keep_prob")
tf.placeholder创建占位符,也就是在训练或测试时将要输入给神经网络的变量。第二个设置项是输入张量的形状。None表示这一维度可以是任意值,使网络可以处理任意数量的批数据。
在dropout层保留一个神经元的概率也是网络的输入之一,因为我们在训练过程中开启了dropout,在评估和与测试这一项会停用。
嵌入层
网络的第一层是嵌入层,将词汇映射到低维向量表征,就像是从数据中学习到一张速查表。
程序说明
词嵌入
示例代码
class TextCNN(object): def __init__(): ... with tf.device('/cpu:0'), tf.name_scope("embedding"): W = tf.Variable(tf.random_uniform([vocab_size, embedding_size], -1.0, 1.0), name="W") self.embedded_chars = tf.nn.embedding_lookup(W, self.input_x) self.embedded_chars_expanded = tf.expand_dims(self.embedded_chars, -1)
注意这里的缩进,以上代码仍然是
def init():中的一部分。
tf.device("/cpu:0"):强制使用CPU。默认情况下TensorFlow会尝试调用GPU,但是词嵌入操作们目前还没有GPU支持,所以有可能会报错。tf.name_scope:新建了一个命名域“embedding”,这样在TensorBoard可视化网络的时候,操作会具有更好的继承性。
W就是我们的嵌入矩阵,也是训练中学习的目标,用随机均匀分布初始化。tf.nn.embedding_lookup创建了实际的嵌入操作,输出结果是3D张量,形如[None, sequence_length, embedding_size]
![]() TensorFlow的卷积操作conv2d接收4维张量[batch, width, height, channel],而我们的嵌入结果没有通道维,所以手动加一个变成[None, sequence_length, embedding, 1]。
TensorFlow的卷积操作conv2d接收4维张量[batch, width, height, channel],而我们的嵌入结果没有通道维,所以手动加一个变成[None, sequence_length, embedding, 1]。
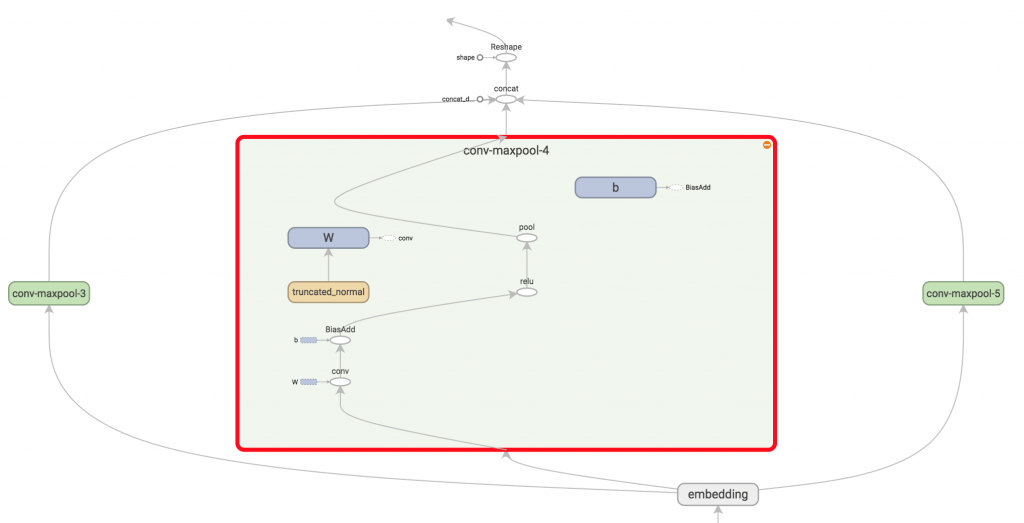
卷积与最大池化层
现在我们来搭建卷积层和紧随其后的池化层,注意我们的卷积核有多种不同的尺寸。因为每个卷积产生的张量形状不一,我们需要迭代对每一个创建一层,然后再把结果融合到一个大特征向量里。
程序说明
卷积+池化
示例代码
class TextCNN(object): def __init__(): ... pooled_outputs = [] for i, filter_size in enumerate(filter_sizes): with tf.name_scope("conv-maxpool-%s" % filter_size): # Convolution Layer filter_shape = [filter_size, embedding_size, 1, num_filters] W = tf.Variable(tf.truncated_normal(filter_shape, stddev=0.1), name="W") b = tf.Variable(tf.constant(0.1, shape=[num_filters]), name="b") conv = tf.nn.conv2d( self.embedded_chars_expanded, W, strides=[1, 1, 1, 1], padding="VALID", name="conv") # Apply nonlinearity h = tf.nn.relu(tf.nn.bias_add(conv, b), name="relu") # Max-pooling over the outputs pooled = tf.nn.max_pool(h, ksize=[1, sequence_length - filter_size + 1, 1, 1], strides=[1, 1, 1, 1], padding='VALID', name="pool") pooled_outputs.append(pooled) # Combine all the pooled features num_filters_total = num_filters * len(filter_sizes) self.h_pool = tf.concat(3, pooled_outputs) self.h_pool_flat = tf.reshape(self.h_pool, [-1, num_filters_total])
这里W是卷积矩阵,h是经过非线性激活函数的输出。每个卷积核都在整个词嵌入空间中扫过,但是每次扫过的个数不一。"VALID" padding 表示卷积核不在边缘做填补,也就是“窄卷积”,输出形状是[1, sequence_length - filter_size + 1, 1, 1]。
最大池化让我们的张量形状变成了[batch_size, 1, 1, num_filters],最后一位对应特征。把所有经过池化的输出张量组合成一个很长的特征向量,形如[batch_size, num_filter_total]。在TensorFlow里,如果需要将高维向量展平,可以在tf.reshape中设置-1。

Dropout
Dropout大概是正则化卷积神经网络最流行的方法。其背后的原理很简单,就是随机“抛弃”一部分神经元,以此防止他们共同适应(co-adapting),并强制他们独立学习有用而特征。不被抛弃的比例我们通过dropout_keep_prob这个变量来控制,训练过程中设为0.5,评估过程中设为1.
程序说明
dropout
示例代码
class TextCNN(object): def __init__(): ... # Add dropout with tf.name_scope("dropout"): self.h_drop = tf.nn.dropout(self.h_pool_flat, self.dropout_keep_prob)
分数与预测
借助最大池化+dropout所得的特征向量,我们可以做个矩阵乘法并选择分数最高的类,来做个预测。当然也可以用softmax函数来把生数据转化成正规化的概率,但这并不会改变最终的预测结果。
程序说明
dropout
示例代码
class TextCNN(object): def __init__(): ... with tf.name_scope("output"): W = tf.Variable(tf.truncated_normal([num_filters_total, num_classes], stddev=0.1), name="W") b = tf.Variable(tf.constant(0.1, shape=[num_classes]), name="b") self.scores = tf.nn.xw_plus_b(self.h_drop, W, b, name="scores") self.predictions = tf.argmax(self.scores, 1, name="predictions")
这里tf.nn.xw_plus_b是$Wx+b$的封装。
损失与精度
有了这个分数即我们就可以定义损失函数了,损失函数(loss)是衡量网络预测误差的指标。我们的目标便是最小化。分类问题中标准的损失函数是交叉熵, cross-entropy loss。
程序说明
dropout
示例代码
class TextCNN(object): def __init__(): ... # Calculate mean cross-entropy loss with tf.name_scope("loss"): losses = tf.nn.softmax_cross_entropy_with_logits(self.scores, self.input_y) self.loss = tf.reduce_mean(losses)
tf.nn.softmax_cross_entropy_with_logits是给定分数和正确输入标签之后,计算交叉熵的函数,然后对损失取平均值。我们也可以求和,但那样的话不同batch size的损失就很难比较了。
我们也定义了精度的表达,这个量在追踪训练和测试过程中很有用。
程序说明
dropout
示例代码
class TextCNN(object): def __init__(): ... # Calculate Accuracy with tf.name_scope("accuracy"): correct_predictions = tf.equal(self.predictions, tf.argmax(self.input_y, 1)) self.accuracy = tf.reduce_mean(tf.cast(correct_predictions, "float"), name="accuracy")
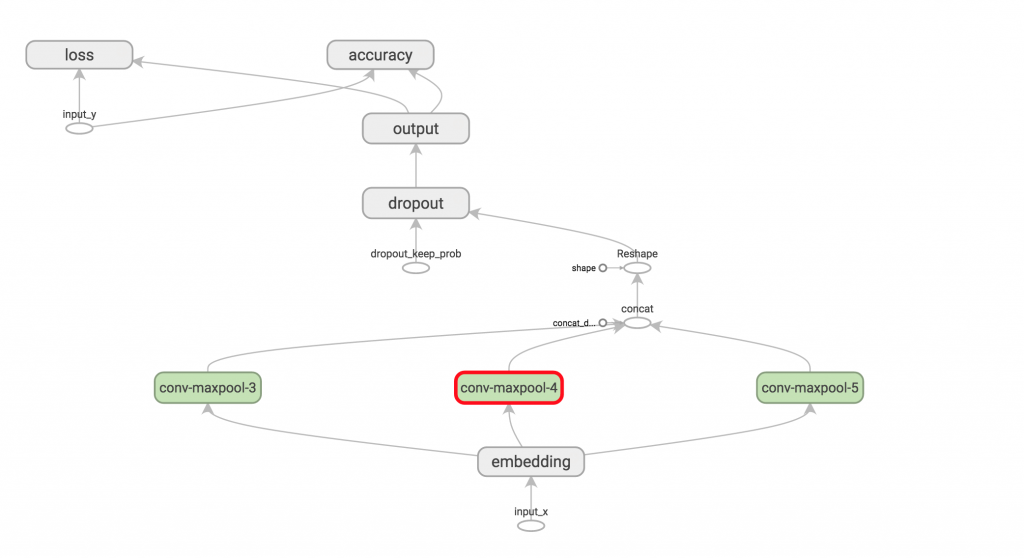
网络可视化
至此我们已经完成了网络的定义工作,通过TensorBoard可视化如下:
训练进程
在启动训练进程之前我们还是有必要了解一些![]() TensorFlow关于“会话”(
TensorFlow关于“会话”(Session)和图(Graphs)的基本概念。如果你已经非常熟悉这一套,可以跳过本节。
TensorFlow 1.5版本已经正式推出,引入了“动态图”机制,因此本文所述并非最新用法。
在TensorFlow当中,Session是执行计算图操作所在的环境,包含变量和队列的状态。每个Session执行一个图,如果没有显式地调用session,那么在创建变量和操作时,就使用TF默认创建的。可以运行命令session.as_default()更改默认session。
一个图(Graph)包含操作和张量,每个程序中可以含有多个图,但大多数程序也只需要一个图就够了。我们可以在多个session中重复使用一个图,但是不能在一个session中调用多个图。TensorFlow会创建默认图,你也可以自行创建新图并设为默认。显式地创建会话和图保证资源在不需要的时候合理释放。
程序说明
会话与图
示例代码
with tf.Graph().as_default(): session_conf = tf.ConfigProto( allow_soft_placement=FLAGS.allow_soft_placement, log_device_placement=FLAGS.log_device_placement) sess = tf.Session(config=session_conf) with sess.as_default(): # Code that operates on the default graph and session comes here...
allow_soft_placement设置允许TensorFlow在指定设备不存在时自动调整设备。例如,如果我们的代码把一个操作放在GPU上,但又在一台没有GPU的机器上运行,如果没有allow_soft_placement就会报错。
如果设置了log_device_placement,TensorFlow日志就会在指定设备(CPU or GPU)上存储日志文件。这对debug很有帮助。FLAGS是程序接收的命令行参数。
CNN实例化,损失最小化
当我们实例化TextCNN模型,所有定义的变量和操作就会被放进默认的计算图和会话。
程序说明
CNN实例化
示例代码
cnn = TextCNN( sequence_length=x_train.shape[1], num_classes=2, vocab_size=len(vocabulary), embedding_size=FLAGS.embedding_dim, filter_sizes=map(int, FLAGS.filter_sizes.split(",")), num_filters=FLAGS.num_filters)
接下来或做的是优化网络损失函数。TensorFlow内置几种优化器,这里使用Adam优化器。
程序说明
Adam
示例代码
global_step = tf.Variable(0, name="global_step", trainable=False) optimizer = tf.train.AdamOptimizer(1e-4) grads_and_vars = optimizer.compute_gradients(cnn.loss) train_op = optimizer.apply_gradients(grads_and_vars, global_step=global_step)
train_op是新建的操作,用来对参数做梯度更新,每一次运行train_op就是一次训练。TensorFlow会自动识别出哪些参数是“可训练的”,然后计算他们的梯度。定义了global_step变量并传入优化器,就可以让TensorFlow来完成计数。每运行一次train_op,global_step就+1。
汇总
(并不是本文的汇总)![]() 有个概念叫summaries,让用户能够追踪并可视化训练和评估过程。比如你可能想知道损失函数和精确度随着时间的变化。更复杂的量也可以检测,比如激活层的柱状图,
Summaries是系列化的对象,通过SummaryWriter写入硬盘。
有个概念叫summaries,让用户能够追踪并可视化训练和评估过程。比如你可能想知道损失函数和精确度随着时间的变化。更复杂的量也可以检测,比如激活层的柱状图,
Summaries是系列化的对象,通过SummaryWriter写入硬盘。
示例代码
# Output directory for models and summaries timestamp = str(int(time.time())) out_dir = os.path.abspath(os.path.join(os.path.curdir, "runs", timestamp)) print("Writing to {}\n".format(out_dir)) # Summaries for loss and accuracy loss_summary = tf.scalar_summary("loss", cnn.loss) acc_summary = tf.scalar_summary("accuracy", cnn.accuracy) # Train Summaries train_summary_op = tf.merge_summary([loss_summary, acc_summary]) train_summary_dir = os.path.join(out_dir, "summaries", "train") train_summary_writer = tf.train.SummaryWriter(train_summary_dir, sess.graph_def) # Dev summaries dev_summary_op = tf.merge_summary([loss_summary, acc_summary]) dev_summary_dir = os.path.join(out_dir, "summaries", "dev") dev_summary_writer = tf.train.SummaryWriter(dev_summary_dir, sess.graph_def)
这里我们分别追踪训练和评估的汇总,有些量是重复的,但又很多量是只在训练过程中想看的(比如参数更新值)。tf.merge_summary函数可以很方便地把合并多个汇总融合到一个操作。
检查点
另一个TensorFlow的特性是checkpointing——存储模型参数,以备不时之需。检查点可以用来继续之前中断的训练,或者提前结束获取最佳参数。检查点是通过Saver对象存储的。
程序说明
Checkpoint
示例代码
# Checkpointing checkpoint_dir = os.path.abspath(os.path.join(out_dir, "checkpoints")) checkpoint_prefix = os.path.join(checkpoint_dir, "model") # Tensorflow assumes this directory already exists so we need to create it if not os.path.exists(checkpoint_dir): os.makedirs(checkpoint_dir) saver = tf.train.Saver(tf.all_variables())
变量初始化
在训练模型之前我们需要初始化计算图中所有的参数:
sess.run(tf.initialize_all_variables())
initialize_all_variables很方便,一次性初始化所有变量。
定义单独训练步
现在来定义一个单独的训练步,来评估模型在一批数据上的表现,并相应地更新参数。
程序说明
train step
示例代码
def train_step(x_batch, y_batch): """ A single training step """ feed_dict = { cnn.input_x: x_batch, cnn.input_y: y_batch, cnn.dropout_keep_prob: FLAGS.dropout_keep_prob } _, step, summaries, loss, accuracy = sess.run( [train_op, global_step, train_summary_op, cnn.loss, cnn.accuracy], feed_dict) time_str = datetime.datetime.now().isoformat() print("{}: step {}, loss {:g}, acc {:g}".format(time_str, step, loss, accuracy)) train_summary_writer.add_summary(summaries, step)
feed_dict里的数据将通过占位符节点送给神经网络,必须让所有节点都有值,否则TensorFlow又要报错了。另一个输入数据的方法是queues,本文先不讨论。
接下来,我们通过session.run()运行train_op,返回值就是我们想我评估的操作结果。注意train_op本身没有返回值,它只是更新了网络参数。最后我们打印出本轮训练的损失函数和精确度,存储汇总至磁盘。loss和accuracy在不同的batch之间可能差异非常大,因为我们的batch_size很小。又因为使用了dropout,所以训练过程开始时的表现可能逊于评估过程。
我们写了一个相似的函数来评估任意数据集的损失和精度,比如验证集或整个训练集。本质上这个函数和之前的一样,但是没有训练操作,也禁用了dropout。
程序说明
train step - 2
示例代码
def dev_step(x_batch, y_batch, writer=None): """ Evaluates model on a dev set """ feed_dict = { cnn.input_x: x_batch, cnn.input_y: y_batch, cnn.dropout_keep_prob: 1.0 } step, summaries, loss, accuracy = sess.run( [global_step, dev_summary_op, cnn.loss, cnn.accuracy], feed_dict) time_str = datetime.datetime.now().isoformat() print("{}: step {}, loss {:g}, acc {:g}".format(time_str, step, loss, accuracy)) if writer: writer.add_summary(summaries, step)
训练循环
最后呢,我们要来写训练循环了。我们一批一批的在数据上迭代,调用train_step函数,然后评估并存储检查点:
程序说明
training loop
示例代码
atch_iter( zip(x_train, y_train), FLAGS.batch_size, FLAGS.num_epochs) # Training loop. For each batch... for batch in batches: x_batch, y_batch = zip(*batch) train_step(x_batch, y_batch) current_step = tf.train.global_step(sess, global_step) if current_step % FLAGS.evaluate_every == 0: print("\nEvaluation:") dev_step(x_dev, y_dev, writer=dev_summary_writer) print("") if current_step % FLAGS.checkpoint_every == 0: path = saver.save(sess, checkpoint_prefix, global_step=current_step) print("Saved model checkpoint to {}\n".format(path))
这里的batch_iter是我写的一个帮助函数,用来给数据分批,tf.train.global_step可以返回global_step的值。训练过程的完整代码可见这里。
TensorBoard可视化结果
我们的训练脚本把汇总写到输出路径,然后把TensorBoard指向那个路径,就可以可视化计算图和汇总。
tensorboard
用默认参数训练(128维词嵌入,卷积核尺寸3、4、5,dropout率为0.5,每种尺寸的卷积核各128个)产出的是如下损失与精度表(蓝色为训练数据,红色是10%的测试数据)。


从图上可以看出几个事:
- 我们的训练曲线并不平滑,因为用了较小的 batch size。如果批量更大一些(甚至在整个训练集上评估),蓝线就会更平滑。
- 因为测试精度明显比训练精度要低,说明我们的网络有些过拟合,这就需要更多数据(MR数据集很小),更强的正则化,或更少的模型参数。比如我尝试了对最后一层的权重加入L2惩罚项,把精度提高到了76%,与原论文的结果接近。
- 训练损失和精度在开始时要比测试过程的差,这是因为dropout。
扩展与练习
有几个练习可以帮助优化我们的模型:
- 用预训练word2vec初始化嵌入,为此你需要用300维的词嵌入。
- 限制最后一层权重向量的L2范数,如原论文所述。可以定义一个新的操作,在每个训练步之后再更新一次权重。
- 加入L2正则化以防过拟合,并实验增大dropout率。
- 加入权重更新的柱状图汇总并用TensorBoard可视化。