2016 CFF reverse write-up
这次在队友的帮助下AK了逆向,有点爽。
程序是把输入跟一串值异或然后与给定的数比较,调试一下,得到异或值
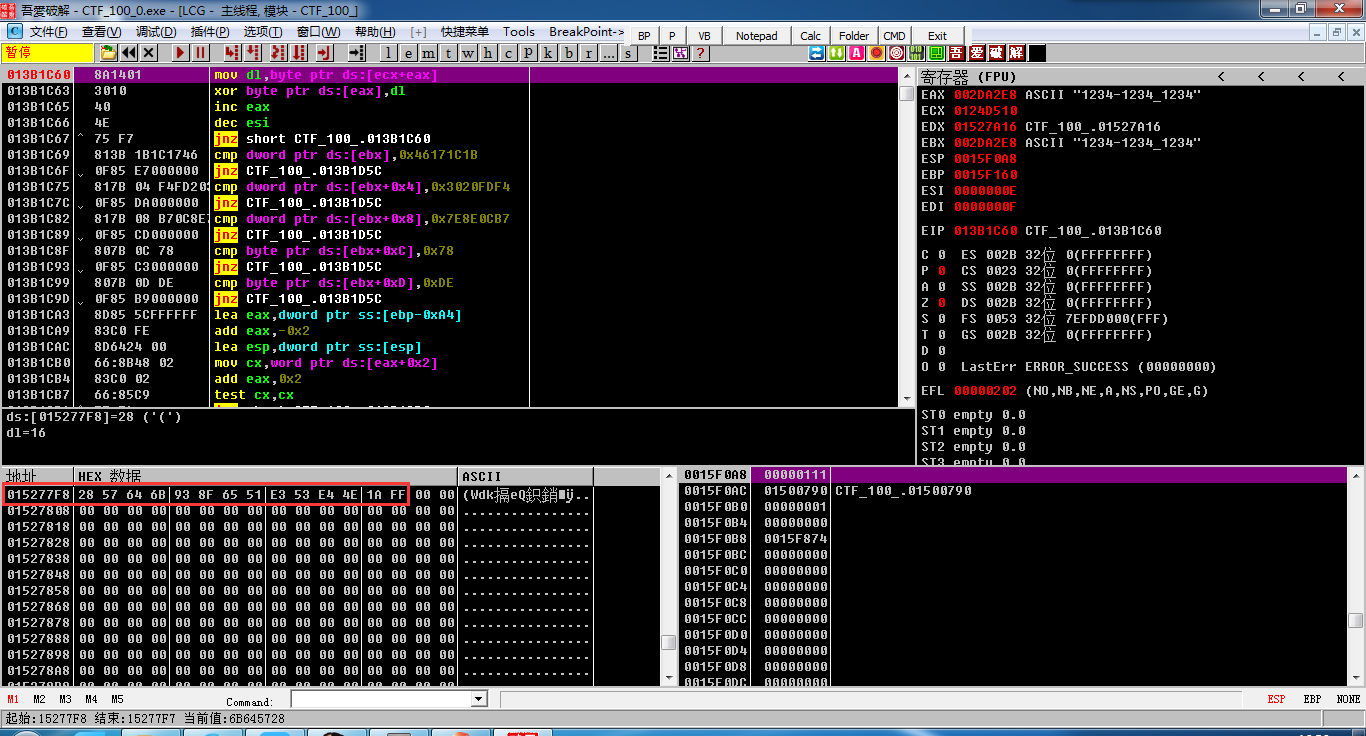
解密
xor = [0x28, 0x57, 0x64, 0x6B, 0x93, 0x8F, 0x65, 0x51, 0xE3, 0x53, 0xE4, 0x4E, 0x1A, 0xFF] result = [0x1B, 0x1C, 0x17, 0x46, 0xF4, 0xFD, 0x20, 0x30, 0xB7, 0x0C, 0x8E, 0x7E, 0x78, 0xDE] flag = '' for i in xrange(len(result)): flag += chr(xor[i] ^ result[i]) print flag
FLAG为3Ks-grEaT_j0b!
Debug blocker反调试,然后在子进程中有一个自修改
Patch一下还原

然后比较
解密
result = [0x25, 0x5C, 0x5C, 0x2B, 0x2F, 0x5D, 0x19, 0x36, 0x2C, 0x64, 0x72, 0x76, 0x80, 0x66, 0x4E, 0x52] table = [0x65, 0x6C, 0x63, 0x6F, 0x6D, 0x65, 0x20, 0x74, 0x6F, 0x20, 0x43, 0x46, 0x46, 0x20, 0x74, 0x65] flag = '' for i in xrange(len(table)): flag += chr((result[i] - 1) ^ table[i]) print flag
FLAG为A78EC98ADC239E94
好多处反调试,还开了一个线程,如果在调试下,对之后的置换表会有影响,可以在程序运行之后输入16个值,然后attach上去,在401970函数开头下个断,然后把置换表dump出来,再把56B110处的4个字节倒置一下就得到了正确的置换表
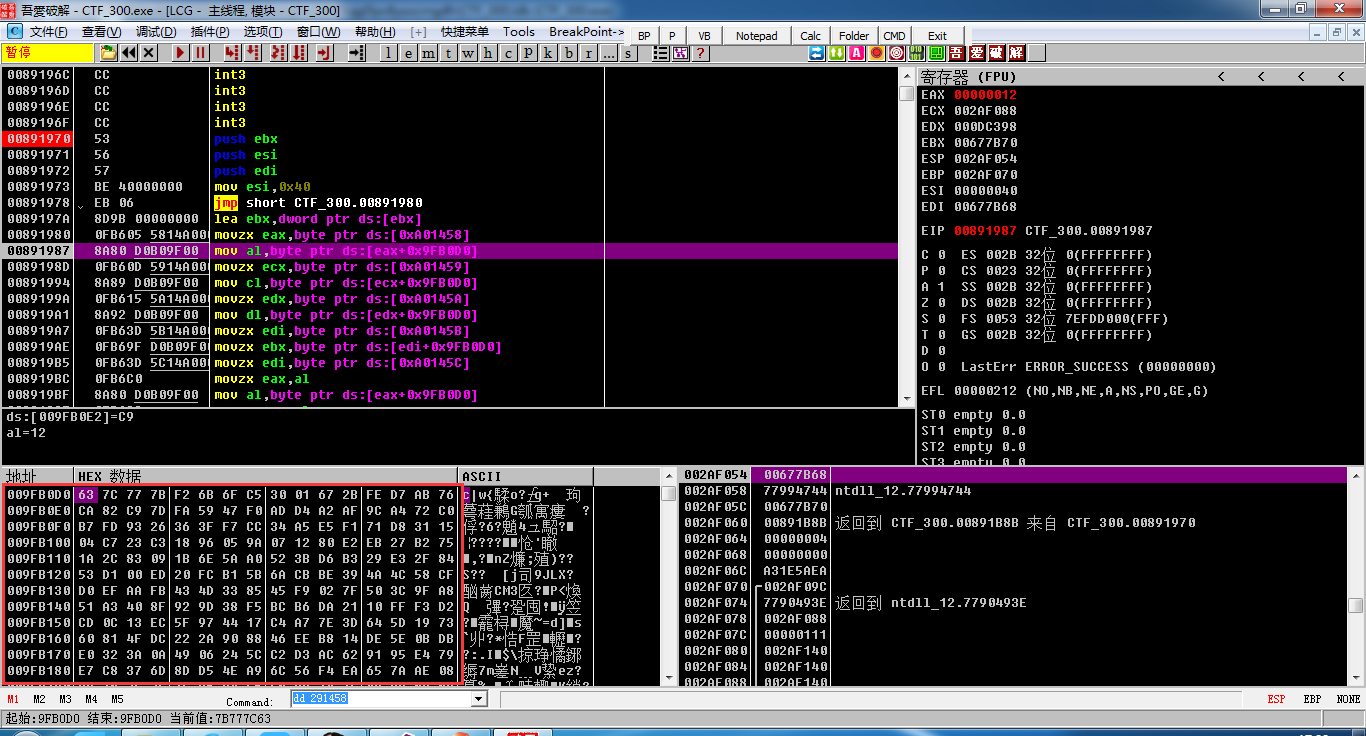
通过测试发现最后每个字节都有一个唯一的输出值,因此生成0-255的输出值,反推回去就行,在最后比较时会有多组符合的解

尝试了几次正确的解应该为55 ,243 ,241 ,44 ,100 ,48 ,110 ,101,也就是w31ld0ne。
FLAG为C7C536FC625CEFCD
解密代码在402570中,程序首先判断加密文件的前4个字节是否为CTF3,然后读取4字节的文件名长度再根据长度读取文件名,然后把之后的16字节与输入的key做两次md5后的结果进行对比
但是由于头部丢失了一部分,只有最后的几个md5,因此接下来的就是爆破
import hashlib
def md5(text):
md5 = hashlib.md5()
md5.update(text)
result1 = md5.digest()
md5 = hashlib.md5()
md5.update(result1)
return md5.hexdigest().upper()
for i in xrange(48, 58):
for j in xrange(48, 58):
for k in xrange(48, 58):
for l in xrange(48, 58):
for m in xrange(48, 58):
for n in xrange(48, 58):
for o in xrange(48, 58):
for p in xrange(48, 58):
key = chr(i) + chr(j) + chr(k) + chr(l) + chr(m) + chr(n) + chr(o) + chr(p)
result = md5(key)
if result.endswith('48B1ED058DF7'):
print 'key=', key得到key为20160610,再修复下头部解密得到一个写着FLAG的docx文件

FLAG为9EBB1B82EDA4F821E17C06E0D5AEBB67
这题的逻辑很清晰,具体步骤为:
1.反调试
2.写注册表自启动,获取用户目录
3.在用户目录及其子目录下搜索docx文件
4.把待加密docx文件放到一个新建的数组中
a) 前4字节写入待加密文件的长度
b) 写入bufFileContent(unicode编码)
c) 写入加密文件
d) 写入bufFileName(unicode编码)
e) 写入待加密文件名

5.加密数组,用到了tea,但是input、key、output都倒置了

6.发送加密之后的数组数据
因此反推就可以解密
int main() {
const string keyStr("84 BE 23 29 AE D6 6C E1 7C 80 EF 87 D2 12 FF B0");
const int SIZE_IN = 8, SIZE_KEY = 16;
byte plain[SIZE_IN], key[SIZE_KEY];
hexStringToBytes(keyStr, key);
TEA tea(key, 16, false);
unsigned char encrypt_data[8] = { 0 };
unsigned char prev_data[8] = { 0x65, 0x0, 0x43, 0x0, 0x6F, 0x0, 0x6E, 0x0 };
unsigned char prev_tea_data[8] = { 73, 107, 43, 213, 129, 235, 149, 66 };
FILE *encrypt_file = fopen("data1.bin", "rb");
FILE *out = fopen("1.bin", "wb+");
while (fread(encrypt_data, 1, 8, encrypt_file)) {
unsigned char tea_encrypt_data[8] = { 0 };
unsigned char tea_encrypt_data2[8] = { 0 };
unsigned char origin_data[8] = { 0 };
int i = 0;
for (i = 0; i < 8; i++) {
tea_encrypt_data[i] = prev_data[i] ^ encrypt_data[i];
}
tea_encrypt_data2[0] = tea_encrypt_data[3];
tea_encrypt_data2[1] = tea_encrypt_data[2];
tea_encrypt_data2[2] = tea_encrypt_data[1];
tea_encrypt_data2[3] = tea_encrypt_data[0];
tea_encrypt_data2[4] = tea_encrypt_data[7];
tea_encrypt_data2[5] = tea_encrypt_data[6];
tea_encrypt_data2[6] = tea_encrypt_data[5];
tea_encrypt_data2[7] = tea_encrypt_data[4];
tea.decrypt(tea_encrypt_data2, plain);
origin_data[0] = plain[3] ^ prev_tea_data[0];
origin_data[1] = plain[2] ^ prev_tea_data[1];
origin_data[2] = plain[1] ^ prev_tea_data[2];
origin_data[3] = plain[0] ^ prev_tea_data[3];
origin_data[4] = plain[7] ^ prev_tea_data[4];
origin_data[5] = plain[6] ^ prev_tea_data[5];
origin_data[6] = plain[5] ^ prev_tea_data[6];
origin_data[7] = plain[4] ^ prev_tea_data[7];
fwrite(origin_data, 1, 8, out);
for (i = 0; i < 8; i++) {
prev_tea_data[i] = tea_encrypt_data[i];
prev_data[i] = origin_data[i];
}
}
fclose(encrypt_file);
fclose(out);
cout << "success" << endl;
return 0;
}解密之后把写flag的docx文件提取出来就行。
FLAG为06423CC23E45DC8867D0B2D93E14C7B5